Bevor irgendeine ethische Einschätzung möglich ist, muss klar sein, worum es eigentlich geht. In dieser ersten Phase wird das Wissen über das Projekt systematisch erschlossen – wer die relevanten Personen sind, welche Dokumente und Systeme existieren, und wie dieses Wissen am effizientesten zugänglich gemacht werden kann.
Methoden wie strukturierte Interviews, kollaborative Workshops oder KI-gestützte Textanalyse kommen je nach Projektstruktur zum Einsatz. Das Ergebnis ist eine strukturierte Wissensbasis, die als Grundlage für die Analyse dient.
Aber der Reihe nach. Willkommen zum Deep Dive #1 – in Phase 1 des Ethics-as-a-Service-Prozess geht es um den Wissensaufbau, denn nur auf einer grundsoliden Wissensbasis können grundsolide Ethik-Assessments (für EU Horizon- oder andere Compliance-Reports) aufgestellt werden. Damit das nicht ewig dauert, sondern lean durchläuft, muss der Prozess durchdacht sein. Also, los gehts:
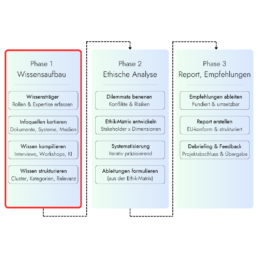
Schritt 1: Wissensträgerim Unternehmen identifizieren
Das ist einer der unterschätztesten Schritte im ganzen Prozess – weil er so selbstverständlich wirkt und in der Praxis so oft unvollständig gemacht wird.
Das Grundproblem
In Startups, besonders im Deep-Tech-Umfeld, ist Wissen selten sauber dokumentiert und auf wenige Personen verteilt. Wer wirklich weiß, wie eine Technologie funktioniert, welche Daten verarbeitet werden oder wer am Ende davon betroffen ist, entspricht oft nicht dem Organigramm. Der CTO weiß Details, die der CEO nicht kennt. Ein externer Berater hat Einblicke, die intern niemand hat. Ein Investor hat Erwartungen, die nirgendwo schriftlich stehen.
Das Schneeball-Prinzip
In der Praxis funktioniert die Identifikation oft wie ein Schneeballverfahren: Jedes Gespräch liefert Hinweise auf weitere Wissensträger. "Für die Frage der Datensicherheit müsstest du eigentlich mit unserem Infrastruktur-Dienstleister reden" – solche Hinweise werden konsequent verfolgt. Der Prozess endet nicht nach dem ersten Durchlauf, sondern erst wenn keine neuen relevanten Namen mehr auftauchen.
Wie ethaas vorgeht
Der Ausgangspunkt ist immer eine strukturierte Erstbefragung – meistens mit der Gründerin oder dem Gründer, der Projektleitung oder wer auch immer den Auftrag gibt. Daraus entsteht eine erste Karte: Wer hat technisches Wissen über das System? Wer kennt die Zielgruppe und ihre Situation? Wer trifft Entscheidungen über die Nutzung der Technologie? Wer ist von den Ergebnissen betroffen, ohne am Projekt beteiligt zu sein?
Diese vier Fragen – Technik, Nutzer, Entscheidung, Betroffenheit – sind der praktische Rahmen. Sie folgen direkt aus dem, was ethisch relevant ist: Nur wer alle vier Perspektiven abgedeckt hat, kann eine belastbare Analyse erstellen.
Wo KI hilft – und wo nicht
Bei der Identifikation relevanter Rollenbezeichnungen in größeren oder komplexeren Organisationen kann KI unterstützen – etwa um sicherzustellen, dass keine typischen Funktionen übersehen werden. Was KI nicht leisten kann: Sie kennt die internen Abläufe, informellen Strukturen und tatsächlichen Wissensverteilungen im konkreten Unternehmen nicht. Der Schritt bleibt deshalb im Wesentlichen ein menschlicher – und ein gesprächsintensiver.

Schritt 2: InformationsquellenkartierenDoku, Systeme, Medien
Auch hier gilt: Was auf den ersten Blick trivial wirkt, ist in der Praxis eine der entscheidenden Weichenstellungen – denn was nicht als Quelle erfasst wird, kann nicht in die Analyse einfließen.
Die wichtigsten Quellenkategorien
In EU-Horizon-Projekten begegnen uns typischerweise vier Arten von Informationsquellen:
Projektdokumentation – Das sind die offensichtlichsten Quellen: Förderantrag, Arbeitspakete, Deliverables, Ethik-Annex, technische Spezifikationen. Diese Dokumente sind oft der beste Einstieg, weil sie das Projekt so beschreiben, wie es gegenüber der EU dargestellt wurde – was nicht immer deckungsgleich ist mit dem, was tatsächlich entwickelt wird.
Interne Unterlagen – Whitepapers, Pitch Decks, Roadmaps, Protokolle, manchmal auch Slack-Verläufe oder interne Wikis. Hier steckt oft das implizite Wissen über Absichten, Zielgruppen und Risikobewusstsein – Dinge, die in keinem offiziellen Dokument stehen.
Externe Quellen – Wissenschaftliche Literatur zur Technologie, regulatorische Vorgaben (z.B. AI Act, DSGVO), branchenspezifische Leitlinien, vergleichbare Technologien und deren bekannte ethische Problemlagen. Gerade bei Deep-Tech-Projekten ist dieser Kontext entscheidend: Was hat die Forschungsgemeinschaft bereits über ähnliche Technologien herausgefunden?
Und natürlich: Menschliche Quellen – Die Wissensträger aus Phase 1. Gespräche und Interviews liefern oft das, was in keinem Dokument steht: Unsicherheiten, Zielkonflikte, informelle Entscheidungen.
Das strukturelle Problem bei Startups: nicht so viel Struktur

Bei Startups ist die Dokumentationslage häufig dünn. Was bei einem etablierten Unternehmen in Handbüchern und Prozessdokumenten steht, lebt im Startup in den Köpfen von drei Personen. Das bedeutet: Der Anteil menschlicher Quellen ist höher, der Aufwand für die Erschließung entsprechend größer.
Was mit den Quellen passiert
Nicht jede Quelle ist gleich relevant, und nicht jede ist gleich zugänglich. Ein Teil der Arbeit in dieser Phase besteht deshalb darin, Quellen zu priorisieren – welche müssen zwingend erschlossen werden, welche liefern ergänzende Tiefe, welche sind nice-to-have? Das hängt vom konkreten Projekt und seinen ethischen Risikoschwerpunkten ab.
Beim Umgang mit sensiblen internen Dokumenten spielt außerdem Datenschutz eine wichtige Rolle: Was an ein KI-System übergeben werden darf und was nicht, wird vor Beginn der Kompilierungsphase geklärt – entweder durch Anonymisierung oder durch den Einsatz datenschutzkonformer Lösungen.
Schritt 3: Wissenkompilierenvon der Quelle zur Nutzung
Das ist die arbeitsintensivste Phase im Wissensaufbau – und gleichzeitig die, bei der der gezielte Einsatz von KI den größten Unterschied macht.
Methode folgt Quelle
Es gibt keine universelle Extraktionsmethode. Was bei einem strukturierten Dokument funktioniert, funktioniert nicht bei einem informellen Gespräch – und was bei einem technisch versierten CTO klappt, ist bei einer Pflegekraft als betroffener Person der falsche Ansatz. Die Methode richtet sich immer nach der Quelle und dem, was aus ihr herausgeholt werden soll.
Dokumentenbasierte Quellen
Hier kommt KI am stärksten zum Tragen. Große Mengen an Projektdokumentation – Förderanträge, Whitepapers, technische Spezifikationen – lassen sich mit KI-Unterstützung clustern, zusammenfassen und auf ethisch relevante Passagen hin durchsuchen.
Was manuell Tage dauern würde, geht so in Stunden. Die entscheidende Einschränkung dabei:
Sensible interne Dokumente dürfen nicht einfach in ein öffentliches KI-System eingespielt werden. Das würde in den meisten Fällen gegen NDA-Vereinbarungen und Datenschutzrecht verstoßen. ethaas klärt deshalb vor Beginn, welche Dokumente wie verarbeitet werden dürfen – und setzt wo nötig auf datenschutzkonforme Alternativen.
MenschlicheQuellen
Bei Interviews und Gesprächen mit Wissensträgern kommen halbstrukturierte Leitfadeninterviews zum Einsatz – offen genug, um Unerwartetes zuzulassen, strukturiert genug, um vergleichbar zu sein. KI kann bei der Vorbereitung helfen: Leitfragen entwickeln, Themencluster vorschlagen, Interviewprotokolle vorstrukturieren. Das Gespräch selbst führt immer ein Mensch.
Bei Workshops – wenn mehrere Wissensträger gleichzeitig einbezogen werden – liegt der Mehrwert in der Interaktion: Widersprüche zwischen Perspektiven werden sichtbar, gemeinsame Einschätzungen entstehen, und Dinge kommen zur Sprache, die im Einzelgespräch nicht auftauchen würden.
Aufbereitung als eigener Schritt
Die Kompilierung endet nicht mit dem Sammeln. Was extrahiert wurde, muss strukturiert werden – kategorisiert, auf Redundanzen geprüft, auf Widersprüche untersucht. Erst in dieser aufbereiteten Form ist das Wissen als Grundlage für die ethische Analyse tauglich. Auch hier leistet KI wertvolle Unterstützung beim Clustern und Zusammenfassen – während die inhaltliche Einschätzung, was relevant ist und was nicht, beim Menschen bleibt.
Was am Ende dieser Phase vorliegt? Eine strukturierte Wissensbasis: Wer ist betroffen und wie? Was tut die Technologie tatsächlich? Welche Entscheidungen wurden bereits getroffen, welche stehen noch aus? Welche Risiken sind intern bereits bekannt – und welche wurden bislang nicht benannt? Auf dieser Grundlage beginnt Phase 2. Vorher bringen wir die Infos noch in Form.
Schritt 4: WissenaufbereitenCluster Kategorien, Relevanz
Das ist der Schritt, der in vielen Assessments stiefmütterlich behandelt wird – dabei entscheidet er maßgeblich darüber, ob die spätere Analyse belastbar ist oder auf wackligem Fundament steht.
Vom Rohstoff zur Analysestruktur
Was nach der Kompilierung vorliegt, ist zunächst ungeordnet: Interviewnotizen neben technischen Spezifikationen neben Förderantragstexten neben Workshop-Protokollen. Unterschiedliche Formate, unterschiedliche Abstraktionsebenen, unterschiedliche Perspektiven – und oft auch widersprüchliche Aussagen. Die Aufbereitung hat die Aufgabe, daraus etwas Kohärentes zu machen.

Schritt 1: Sichten und auf Relevanz prüfen
Nicht alles, was gesammelt wurde, ist für die ethische Analyse gleich wichtig. Ein erster Durchgang sortiert das Material grob: Was ist zentral, was ergänzend, was kann beiseitegelegt werden? KI kann hier helfen, große Dokumentenmengen schnell zu überblicken – die inhaltliche Relevanzbewertung braucht aber einen Menschen, der weiß, worauf es im konkreten Förderkontext ankommt.
Schritt 2: Kategorisieren
Das relevante Material wird thematisch geclustert. Typische Kategorien sind etwa: Daten und Datenschutz, betroffene Personengruppen, Entscheidungsautonomie, Risiken für Dritte, regulatorischer Kontext. Diese Kategorien sind nicht fix – sie entstehen aus dem Material selbst und orientieren sich an den ethischen Dimensionen, die in Phase 2 in der Matrix abgebildet werden sollen. Auch hier leistet KI gute Dienste beim Vorstrukturieren.
Schritt 3: Widersprüche markieren
Das ist der Schritt, der am meisten Erfahrung erfordert – und der am wenigsten automatisierbar ist. Widersprüche entstehen, wenn verschiedene Wissensträger dasselbe Thema unterschiedlich einschätzen, wenn die offizielle Projektdokumentation nicht mit der tatsächlichen Entwicklung übereinstimmt, oder wenn implizite Annahmen im Material kollidieren. Diese Widersprüche werden nicht aufgelöst, sondern zunächst explizit gemacht – sie sind oft die ethisch relevantesten Stellen im ganzen Material.
Schritt 4: Analysebasis formulieren
Am Ende steht ein strukturiertes Bild des Projekts: Was tut die Technologie? Wer ist betroffen und wie? Welche Entscheidungen wurden bereits getroffen? Wo liegen die bekannten und die noch nicht benannten Risiken? Dieses Bild ist der direkte Input für die Ethik-Matrix in Phase 2 – und je sorgfältiger es erarbeitet wurde, desto belastbarer sind die späteren Ableitungen.

