Before any ethical assessment is possible, it’s essential to understand the project’s core issues. This initial phase systematically gathers knowledge about the project – identifying the relevant individuals, identifying existing documents and systems, and determining the most efficient way to access this knowledge.
Depending on the project structure, methods such as structured interviews, collaborative workshops, or AI-supported text analysis are employed. The result is a structured knowledge base that serves as the foundation for analysis.
But let’s start at the beginning. Welcome to Deep Dive #1 – Phase 1 of the Ethics-as-a-Service process focuses on knowledge building, because only a solid knowledge base allows for sound ethics assessments (for EU Horizon or other compliance reports). To ensure this process is efficient and streamlined, the approach must be well-designed. So, let’s get started:
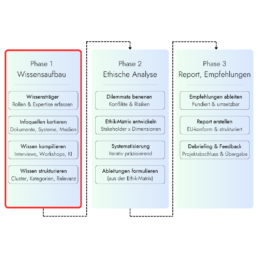
Step 1: Identifying theKnowledge Carriers
This is one of the most underestimated steps in the entire process – because it seems so obvious and is so often done incompletely in practice.
The fundamental problem
In startups, especially in the deep tech sector, knowledge is rarely well-documented and is often concentrated in the hands of a few people. Who truly understands how a technology works, what data is processed, or who is ultimately affected by it often doesn't fit into the organizational chart. The CTO knows details the CEO doesn't. An external consultant has insights no one internally possesses. An investor has expectations that aren't written down anywhere.
The snowball effect
In practice, identification often works like a snowball effect: every conversation provides clues to other individuals with relevant knowledge. "For the data security issue, you should really talk to our infrastructure service provider" – such leads are followed up rigorously. The process doesn't end after the first round, but only when no new relevant names emerge.
How Ethaas proceeds
The starting point is always a structured initial interview – usually with the founder, the project manager, or whoever commissioned the project. This results in an initial map: Who has technical knowledge of the system? Who knows the target group and their situation? Who makes decisions about the use of the technology? Who is affected by the results without being involved in the project?
These four questions – technology, users, decision-making, and impact – form the practical framework. They follow directly from what is ethically relevant: Only those who have covered all four perspectives can create a reliable analysis.
Where AI helps – and where it doesn't
AI can assist in identifying relevant role titles in larger or more complex organizations – for example, to ensure that no typical functions are overlooked. However, AI cannot do this: it doesn't know the internal processes, informal structures, and actual knowledge distributions within a specific company. Therefore, this step remains essentially a human one – and one that requires extensive dialogue.

Step 2: MappingInformation
Here too, the following applies: What seems trivial at first glance is in practice one of the crucial turning points – because what is not recorded as a source cannot be included in the analysis.
The most important source categories
In EU Horizon projects, we typically encounter four types of information sources:
Project documentation – these are the most obvious sources: grant application, work packages, deliverables, ethics annex, technical specifications. These documents are often the best starting point because they describe the project as it was presented to the EU – which is not always identical to what is actually being developed.
Internal documents – white papers, pitch decks, roadmaps, meeting minutes, sometimes even Slack conversations or internal wikis. These often contain implicit knowledge about intentions, target groups, and risk awareness – things that aren’t found in any official document.
External sources – Scientific literature on the technology, regulatory requirements (e.g., AI Act, GDPR), industry-specific guidelines, comparable technologies and their known ethical issues. This context is particularly crucial for deep-tech projects: What has the research community already discovered about similar technologies?
And of course: Human sources – the knowledge holders from Phase 1. Conversations and interviews often provide what is not in any document: uncertainties, conflicting goals, informal decisions.
The structural problem with startups: not so much structure.

In startups, documentation is often sparse. What an established company would write in manuals and process documents, in a startup exists only in the minds of three people. This means that the proportion of human sources is higher, and the effort required to access them is correspondingly greater.
What happens to the sources
Not every source is equally relevant, and not every source is equally accessible. Part of the work in this phase therefore involves prioritizing sources – which ones are essential, which provide additional depth, and which are nice-to-have? This depends on the specific project and its ethical risk priorities.
Data protection also plays an important role when dealing with sensitive internal documents: What may and may not be passed on to an AI system is clarified before the start of the compilation phase – either through anonymization or through the use of data protection-compliant solutions.
Step 3: KnowledgeCompilation
This is the most labor-intensive phase in knowledge building – and at the same time the one where the targeted use of AI makes the biggest difference.
Method follows source
There is no universal extraction method. What works for a structured document doesn't work for an informal conversation – and what works for a technically skilled CTO is the wrong approach for a caregiver as the person affected. The method always depends on the source and what needs to be extracted from it.
Document-based sources
This is where AI has the greatest impact. Large amounts of project documentation – grant applications, white papers, technical specifications – can be clustered, summarized, and searched for ethically relevant passages with AI support.
What would take days manually can now be done in hours. The crucial limitation is:
Sensitive internal documents cannot simply be fed into a public AI system. In most cases, this would violate NDAs and data protection laws. Therefore, ethaas clarifies in advance which documents may be processed and how – and, where necessary, uses data protection-compliant alternatives.
HumanSources
Bei Interviews und Gesprächen mit Wissensträgern kommen halbstrukturierte Leitfadeninterviews zum Einsatz – offen genug, um Unerwartetes zuzulassen, strukturiert genug, um vergleichbar zu sein. KI kann bei der Vorbereitung helfen: Leitfragen entwickeln, Themencluster vorschlagen, Interviewprotokolle vorstrukturieren. Das Gespräch selbst führt immer ein Mensch.
In workshops – when several knowledge holders are involved simultaneously – the added value lies in the interaction: contradictions between perspectives become visible, common assessments emerge, and things are brought up that would not come up in individual conversations.
Preparation as a separate step
The compilation process doesn’t end with data collection. What has been extracted must be structured – categorized, checked for redundancies, and examined for contradictions. Only in this processed form is the knowledge suitable as a basis for ethical analysis. Here, too, AI provides valuable support in clustering and summarizing – while the substantive assessment of what is relevant and what is not remains with humans.
What will we have at the end of this phase? A structured knowledge base: Who is affected and how? What does the technology actually do? Which decisions have already been made, and which are still pending? Which risks are already known internally – and which have not yet been identified? Phase 2 begins based on this information. Before that, we’ll organize the information.
Schritt 4: KnowledgeProcessingClusters, Categories, Relevance
This is the step that is often neglected in many assessments – yet it significantly determines whether the subsequent analysis is reliable or based on shaky foundations.
From raw material to analytical structure
What emerges after compilation is initially disorganized: interview notes alongside technical specifications, grant proposal texts, and workshop minutes. Different formats, different levels of abstraction, different perspectives – and often contradictory statements. The task of processing this material is to create something coherent.

Step 1: Review and check for relevance
Not everything that has been collected is equally important for ethical analysis. An initial review roughly sorts the material: What is central, what is supplementary, what can be set aside? AI can help here to quickly survey large amounts of documents – but the assessment of content relevance requires a human who knows what matters in the specific funding context.
Step 2: Categorize
The relevant material is clustered thematically. Typical categories include: data and data protection, affected groups, autonomy in decision-making, risks to third parties, and the regulatory context. These categories are not fixed – they emerge from the material itself and are based on the ethical dimensions that will be mapped in the matrix in Phase 2. Here, too, AI proves useful in pre-structuring the material.
Step 3: Highlight contradictions
This is the step that requires the most experience – and is the least automatable. Contradictions arise when different knowledge holders assess the same topic differently, when the official project documentation does not correspond with the actual development, or when implicit assumptions in the material clash. These contradictions are not resolved, but rather made explicit – they are often the most ethically relevant points in the entire material.
Step 4: Formulate the basis for analysis
The end result is a structured picture of the project: What does the technology do? Who is affected and how? What decisions have already been made? What are the known and unidentified risks? This picture is the direct input for the ethics matrix in Phase 2 – and the more carefully it is developed, the more robust the subsequent conclusions will be.